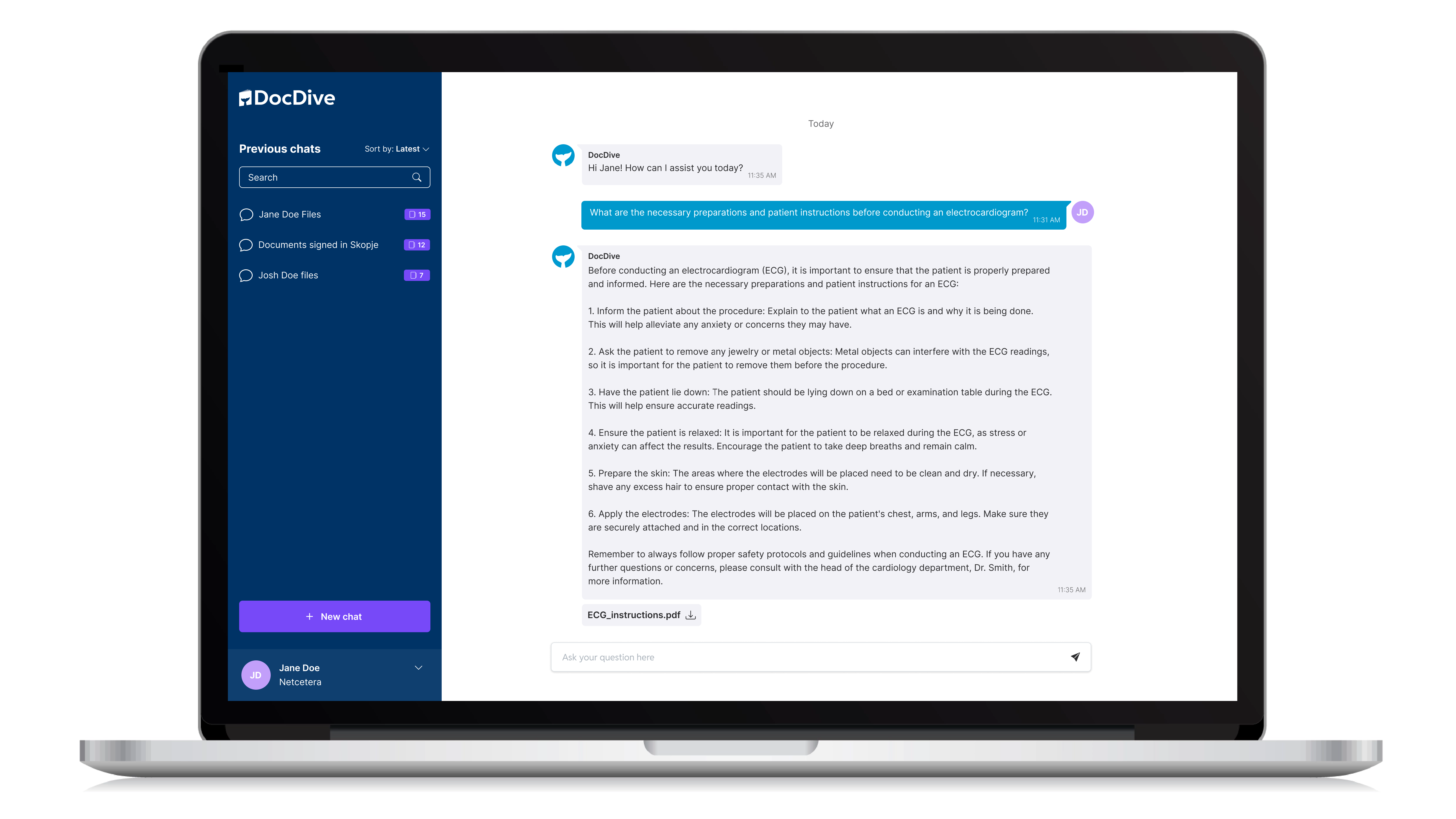
During your workday, perhaps you need to look up relevant information or instructions in a manual with hundreds of pages or in an online tool. It probably has become kind of a routine and you have created your ways to search for the right part of it. How about just entering the question you have, and your smart assistant will give you the answer with a direct reference to the related content in the original document.
Large Language Models (LLM) facilitates information search
The development of large language models (LLM) has made this possible. There are many new models around, such as ChatGPT, Gemini, Bard and others.
Basically, it’s possible to ask a question in natural language and you get an answer in natural language. As simple as that.
It works for all industries and topics. Such as in Healthcare, where countless guidelines need to be observed, or in Mobility, where instructions depending on the case need to be checked, or in Finance where regulation and compliance require a lot of instructions need to be observed.
What obstacles could I encounter and how can I work around them?Like many things in life, this is also not that easy. The publicly available models use publicly available information and data that has been fed into them, either on purpose or by not being aware of it. And that is exactly where some of the hurdles for easy use lies.
In a business context information searched for is often confidential, for internal purpose only or even protected by a patent. To name a view of the reasons not to use a public model for most of the business needs.
There are large language models available as open source, already pre-trained with carefully curated data from one or multiple specific domains. To make it usable for your own purposes and most important keep your information you feed in private, the model needs to be fitted with your own input
Security and data protection
Wasn’t there something about privacy earlier in this text? Yes. And this is why you should not put your information in a publicly available model, but in one that is exactly tailored for your needs. The good news is that Netcetera has already prepared the ingredients for this.
DocDive Chatbot meets security and business requirements
We have created a tool called DocDive, based on Generative AI, which allows exactly to handle your privacy but benefits from open-source models.
Markus Dietrich
Head sales Digital Enterprise
More stories
On this topic